A Greedy Approximation Algorithm for the Linear Assignment Problem
Starting today, I will be posting some of the related source code for articles on GitHub.
Introduction
The Linear Assignment Problem (LAP) is concerned with uniquely matching an equal number of workers to tasks, 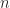


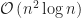
Linear Assignment Problem

The above linear program has cost, 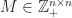

From a practical point of view, we may relax the integral constraint on 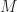

Algorithms
Brute Force Rather than using the mathematical programming or graph theoretic representation of the problem, we can instead view the problem as finding the assignment that minimizes the cost out of all possible assignments:
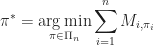
There are 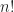


Random The random algorithm selects a permutation 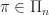

Greedy The greedy heuristic continues to cover the row and column of the smallest uncovered entry in the cost matrix until all entries are covered. The resulting set of entries then constitutes the assignment of workers to jobs. An inefficient 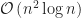
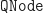

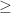

Algorithm 1 A greedy algorithm for the LAP.
// Adjacent node left, above, right, below properties
// Sort in ascending order by node value
// Adjacent node previous and next properties
// Deletes row and col of

![A[i] \gets \bot \text{ for } i = 0 \ldots n - 1](https://s0.wp.com/latex.php?latex=A%5Bi%5D+%5Cgets+%5Cbot+%5Ctext%7B+for+%7D+i+%3D+0+%5Cldots+n+-+1&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
![Q[i] \gets \texttt{QNode} \text{ for } i = 0 \ldots n^2 - 1](https://s0.wp.com/latex.php?latex=Q%5Bi%5D+%5Cgets+%5Ctexttt%7BQNode%7D+%5Ctext%7B+for+%7D+i+%3D+0+%5Cldots+n%5E2+-+1&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
![\qquad Q_{min} \gets Q[0]](https://s0.wp.com/latex.php?latex=%5Cqquad+Q_%7Bmin%7D+%5Cgets+Q%5B0%5D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
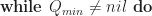
![A[ Q_{min} \rightarrow row ] \gets Q_{min} \rightarrow col](https://s0.wp.com/latex.php?latex=A%5B+Q_%7Bmin%7D+%5Crightarrow+row+%5D+%5Cgets+Q_%7Bmin%7D+%5Crightarrow+col&bg=ffffff&fg=1c1c1c&s=0&c=20201002)



Allocating and linking for assignment is 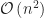


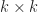


Breaking ties for the minimum uncovered value can result in different costs. This drawback is shown in the above example were choosing 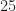




Hungarian The general idea behind the Kuhn-Munkres algorithm is that if we are given an initial assignment, we can make further assignments and potentially reassign workers until all workers have been tasked with a job. The high-level sketch of the algorithm starts with an initial assignment. While we have jobs that are unassigned, we look for qualified workers, ie, the zero entries. If a worker is already assigned to a job, but is also qualified for another, then we prime the alternative and continue to the next qualified worker, but if that is the only job the worker is qualified for, then we’d like to reassign any other worker already tasked to that job. This leads to a natural ripple effect represented by an alternating path of starred and primed entries. In Munkres’ paper [9] “starred” zero’s represent assignments of workers to jobs, and “primed” zero’s are alternative assignments. By flipping the bits of the path, we reassign workers to their alternative tasks while ensuring the assignment continues to be minimal by construction. After assigning as many workers as we have to, we then deduct the lowest cost to create a new qualified worker. Thus, every iteration we are guaranteed to make positive progress towards our goal of finding an optimal assignment. This scheme results in the worst case
Algorithm 2 The Hungarian method for the LAP.
- Star the first uncovered zero in row
, cover the corresponding column
for
All columns not covered
- Prime the current uncovered zero
There’s a starred zero in this row
- Uncover the starred zero’s column and cover the row
-
- Find an alternating augmented path from the primed zero
- Unstar the starred zeros on the path and star the primed zeros on the path
- Remove all the prime markings and cover all stared zeros
-
over all uncovered
for all uncovered columns
for all covered rows
Starred zeros // These are all the assignments
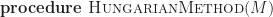
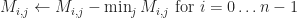






To further illustrate the algorithm, consider the following example where starred entries are denoted by red, and primed entries by green:

Analysis
The prevailing convention in the literature is to look at the approximation factor, 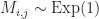

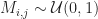
Exponential Distribution Properties Let 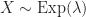





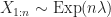


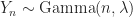

Expected Minimum Cost The expected minimum assignment cost for

Which is the generalized harmonic number of order two and converges to 
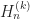


Greedy The minimum value of an 
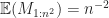

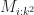
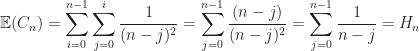
This is the harmonic number of order one which does not converge. The resulting approximation factor is:

Random The random algorithm will simply select an assignment permutation, so we are just adding up 

And approximation factor:

From this analysis one concludes that the greedy algorithm has an unbounded approximation factor that grows significantly slower than that of randomly selecting assignments.
Evaluation

To illustrate the preceding results, Figure 1 shows the approximation factor for the greedy algorithm implementations against the derived approximation factor. The simulated results are based on 120 
| Solver | MSE |
|---|---|
| GREEDY-EFFICIENT | 0.002139 |
| GREEDY-NAIVE | 0.014161 |
| HUNGARIAN | 0.232998 |
Summary
| Brute | Random | Greedy | Hungarian | |
|---|---|---|---|---|
| Complexity | |
|
|
|
 |
1 | 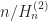 |
 |
1 |
Exact solutions can be delivered by the brute method when a handful of workers are being considered, and the Hungarian method should be considered for all other instances. Approximate solutions can be provided by the greedy algorithm with logarithmic degeneracy while providing a linear factor improvement over the Hungarian method. For inputs greater than those considered, the parallel Auction algorithm [3] is a suitable alternative and the subject of future work.
References
- Aldous, D. J. The
limit in the random assignment problem. Random Structures & Algorithms 18, 4 (2001), 381-418.
- Balakrishnan, N., and Rao, C. Handbook of statistics 16: Order statistics-theory and methods, 2000.
- Bertsekas, D. P. The auction algorithm: A distributed relaxation method for the assignment problem. Annals of operation research 4, 1 (1988), 105-123.
- Durtenfeld, R. Algorithm 235: random permutation. Communications of the ACM 7, 7 (1964), 420.
- Heap, B. Permutations by interchanges. The Computer Journal 6, 3 (1963), 293-298.
- Kuhn, H. W. The hungarian method for the assignment problem. Naval research logistics quarterly 2, 1-2 (1955), 83097.
- Kurtzberg, J. M. On approximation methods for the assignment problem. Journal of the ACM (JACM) 9, 4 (1962), 419-439.
- Steele, M. J. Probability and statistics in the service of computer science: illustrations using the assignment problem. Communications in Statistics-Theory and Methods 19, 11 (1990), 4315-4329.
- Munkres, J. Algorithms for the assignment and transportation problems. Journal of the society for industrial and applied mathematics 5, 1 (1957), 32-38.
- Williamson, D. P., and Shmoys, D. B. The design of approximation algorithms. Cambridge university press, 2011.

Leave a comment