GPU Accelerated Expectation Maximization for Gaussian Mixture Models using CUDA
C, CUDA, and Python source code available on GitHub
Introduction
Gaussian Mixture Models [1, 435-439] offer a simple way to capture complex densities by employing a linear combination of 

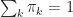

Of practical interest is the learning of the number of components and the values of the parameters. Evaluation criteria, such as Akaike and Bayesian, can be used to identify the number of components, or non-parametric models like Dirichlet processes can be used to avoid the matter all together. We won’t cover these techniques here, but will instead focus on finding the values of the parameters given sufficient training data using the Expectation-Maximization algorithm [3], and doing so efficiently on the GPU. Technical considerations will be discussed and the work will conclude with an empirical evaluation of sequential and parallel implementations for the CPU, and a massively parallel implementation for the GPU for varying numbers of components, points, and point dimensions.
Multivariate Normal Distribution
The multivariate normal distribution With mean, 
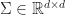
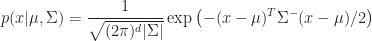
From a computational perspective, we will be interested in evaluating the density for 




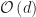



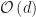
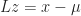

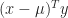
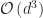
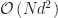

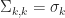

To avoid numerical issues such as overflow and underflow, we’re going to consider 

Expectation Maximization
From an unsupervised learning point of view, GMMs can be seen as a generalization of k-means allowing for partial assignment of points to multiple classes. A possible classifier is given by 
![\displaystyle \mathcal{L} \left( \mathcal{D} \lvert \mu, \Sigma \right) = \sum_{n = 1}^{N} \log p(x_n) = \sum_{n=1}^{N} \log{ \left [ \sum_{k = 1}^{K} \pi_{k} p \left( x_n \lvert \mu_k, \Sigma_k \right ) \right ] }](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BL%7D+%5Cleft%28+%5Cmathcal%7BD%7D+%5Clvert+%5Cmu%2C+%5CSigma+%5Cright%29+%3D+%5Csum_%7Bn+%3D+1%7D%5E%7BN%7D+%5Clog+p%28x_n%29+%3D+%5Csum_%7Bn%3D1%7D%5E%7BN%7D+%5Clog%7B+%5Cleft+%5B+%5Csum_%7Bk+%3D+1%7D%5E%7BK%7D+%5Cpi_%7Bk%7D+p+%5Cleft%28+x_n+%5Clvert+%5Cmu_k%2C+%5CSigma_k+%5Cright+%29+%5Cright+%5D+%7D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
Because we are dealing with exponents and logarithms, it’s very easy to end up with underflow and overflow situations, so we’ll continue the trend of working in log-space and also make use of the “log-sum-exp trick” to avoid these complications:
![\displaystyle \log p( x ) = a + \log \left[ \sum_{k = 1}^{K} \exp{ \left( \log \pi_{k} + \log p(x \lvert \mu_k, \Sigma_k) - a \right ) } \right ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog+p%28+x+%29+%3D+a+%2B+%5Clog+%5Cleft%5B+%5Csum_%7Bk+%3D+1%7D%5E%7BK%7D+%5Cexp%7B+%5Cleft%28+%5Clog+%5Cpi_%7Bk%7D+%2B+%5Clog+p%28x+%5Clvert+%5Cmu_k%2C+%5CSigma_k%29+-+a+%5Cright+%29+%7D+%5Cright+%5D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
Where the 

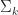


![\displaystyle \log \gamma_{k, n} = \log p \left ( x_n \lvert \mu_k, \Sigma_k \right ) - \log p(x) \qquad \log \Gamma_k = a + \log \left [ \sum_{n=1}^{N} \exp{ \left( \log \gamma_{k, n} - a \right )} \right ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog+%5Cgamma_%7Bk%2C+n%7D+%3D++%5Clog+p+%5Cleft+%28+x_n+%5Clvert+%5Cmu_k%2C+%5CSigma_k+%5Cright+%29++-+%5Clog+p%28x%29+%5Cqquad+%5Clog+%5CGamma_k+%3D+a+%2B+%5Clog+%5Cleft+%5B+%5Csum_%7Bn%3D1%7D%5E%7BN%7D+%5Cexp%7B+%5Cleft%28+%5Clog+%5Cgamma_%7Bk%2C+n%7D+-+a+%5Cright+%29%7D+%5Cright+%5D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
The new parameters are resolved within the maximization step:
![\displaystyle \pi_{k}^{(t+1)} = \frac{ \pi_{k}^{(t)} \Gamma_k }{ \sum_{i=1}^{K} \pi_{i}^{(t)} \Gamma_i } \qquad \log \pi_{k}^{(t+1)} = \log \pi_{k}^{(t)} + \log \Gamma_k - a - \log \left [ \sum_{i=1}^{K} \exp{ \left( \log \pi_{i}^{(t)} + \log \Gamma_i - a \right )} \right ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpi_%7Bk%7D%5E%7B%28t%2B1%29%7D+%3D+%5Cfrac%7B+%5Cpi_%7Bk%7D%5E%7B%28t%29%7D+%5CGamma_k+%7D%7B+%5Csum_%7Bi%3D1%7D%5E%7BK%7D+%5Cpi_%7Bi%7D%5E%7B%28t%29%7D+%5CGamma_i+%7D+%5Cqquad+%5Clog+%5Cpi_%7Bk%7D%5E%7B%28t%2B1%29%7D+%3D+%5Clog+%5Cpi_%7Bk%7D%5E%7B%28t%29%7D+%2B+%5Clog+%5CGamma_k+-+a+-+%5Clog+%5Cleft+%5B+%5Csum_%7Bi%3D1%7D%5E%7BK%7D+%5Cexp%7B+%5Cleft%28+%5Clog+%5Cpi_%7Bi%7D%5E%7B%28t%29%7D+%2B+%5Clog+%5CGamma_i+-+a+%5Cright+%29%7D+%5Cright+%5D+&bg=ffffff&fg=1c1c1c&s=0&c=20201002)

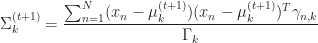

The algorithm continues back and forth between expectation and maximization stages until the change in log likelihood is less than some epsilon, or a maximum number of user specified iterations has elapsed.
Implementations
Sequential Per iteration complexity given by 
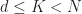

Parallel There are two natural data parallelisms that appear in the algorithm. The calculation of the 
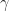

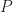

Massively Parallel The parallel implementation can be taken and mapped over to the GPU with parallelism taken across points and components depending on the terms being computed. There are several types of parallelism that we will leverage under the CUDA programming model. For the calculation of 

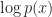

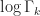
The main design consideration was whether or not use streams. For larger numbers of components, this will result in improved runtime performance, however, it comes at the cost of increased memory usage which limits the size of problems an end user can study with the implementation. Because the primary design goal is performance, the increase in memory was favorable to using less memory and executing each component sequentially.
To optimize the runtime of the implementation nvprof along with the NVIDIA Visual Profiler was used to identify performance bottlenecks. The original implementation was a naive port of the parallel C code which required frequent memory transfers between host and device resulting in significant CUDA API overhead that dominated the runtime. By transferring and allocating memory on the device beforehand, this allowed the implementation to execute primarily on the GPU and eliminate the API overhead. The second primary optimization was using streams and events for parallelization of the component probability densities and parameter updates in the maximization step. In doing so, this allowed for a
Evaluation
To evaluate the implementations we need a way of generating GMMs and sampling data from the resulting distributions. To sample from a standard univariate normal distribution one can use The Box-Muller transform, Zigguart method, or Ratio-of-uniforms method [7]. The latter is used here due to its simplicity and efficiency. Sampling from the multivariate normal distribution can by done by sampling a standard normal vector 
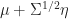


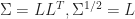

The matter of generating GMMs it more interesting. Here we draw 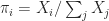
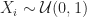


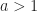



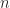


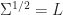




To evaluate the performance of the different implementations, the wall clock time taken to run the algorithm on a synthetic instance was measured by varying each of the 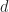

Since the parameter space is relatively large Figures 2-5 look at varying one parameter will fixing the others to demonstrate the relative merits of each approach. When the number of points dominates the CUDA approach tends to be 18x faster; the Parallel approach tends to be 3x faster when the dimension is high; and CUDA is suitable when the num of components is high giving a 20x improvement relative to the sequential approach. Thus, when dealing with suitably large datasets, the CUDA based implementation is preferable delivering superior runtime performance without sacrificing quality.
It is important to note that the results obtained from the CUDA solution may differ to those the sequential and parallel approaches. This is due to nondeterministic round off errors associated with executing parallel reductions compared to sequential reductions [2], and differences in the handling of floating point values on the GPU [10], notably, the presence of fused multiple add on NVIDIA GPUs which are more accurate than what is frequently implemented in CPU architectures. The following two synthetic data sets illustrate typical results of the three schemes:

Conclusion
This work demonstrated the utility of using NVIDIA GPUs to train Gaussian mixture models by the Expectation Maximization algorithm. Speedups as high as 20x were observed on synthetic datasets by varying the number of points, components, and data dimension while leaving the others fixed. It is believed that further speedups should be possible with additional passes, and the inclusion of metric data structures to limit which data is considered during calculations. Future work would pursue more memory efficient solutions on the GPU to allow for larger problem instance, and focus on providing higher level language bindings so that it can be better utilized in traditional data science toolchains.
References
- Bishop, C. M. Pattern recognition and machine learning. Springer, 2006.
- Collange, S., Defour, D., Graillat, S., and Lakymhuk, R. Numerical reproducibility for the parallel reduction on multi- and many-core architectures. Parallel Computing 49 (2015), 83-97.
- Dempster, A. P., Laird, N. M., and Rubin, D. B. Maximum likelihood from incomplete data via the eme algorithm. Journal of the royal statistical society. Series B (methodological) (1977), 1-38.
- Fan, J., Liao, Y., and Liu, H. An overview of the estimation of large covariance and precision matrices. The Econometrics Journal 19, (2016) C1-C32.
- Harris, M. Optimizing cuda. SC07: High Performance Computing with CUDA (2007).
- Kincaid, D., and Cheney, W. Numerical analysis: mathematics of scientific computing. 3 ed. Brooks/Cole, 2002.
- Kinderman, A. J., and Monahan, J. F. Computer generation of random variables using the ratio of uniform deviates. ACM Transactions on Mathematical Software (TOMS) 3, 3 (1977), 257-260.
- Odell, P., and Feiveson, A. A Numerical procedure to generate a sample covariance matrix. Journal of the American Statistical Association 61, 313 (1966), 199-203.
- Sawyer, S. Wishart distributions and inverse-wishart sampling. URL: http://www.math.wustl.edu/~sawyer/hmhandouts/Wishart.pdf (2007).
- Whitehead, N., and Fit-Florea, A. Precision and performance: Floating point and ieee 754 compliance for nvidia gpus. rn(A + B) 21., 1 (2011), 18749-19424.

Leave a comment