Parallel Merge Sort in Java
Introduction
This past November I was a pretty busy getting settled into a new job and trying to balance life’s other priorities. With a new job also came a new technology stack and while I’ll continue to do C# development in my free time, I’m going to be going back to doing Java development after a seven year hiatus. Before starting the new job, I decided to refresh my memory of the language’s finer details when it comes to generics and threading. So, I decided to implement something simple and settled on a parallel implementation of merge sort. This article is going to focus on making use of Java’s various features and evaluating the theoretical and empirical run time performance of the sequential and parallel versions of the algorithm.
Sequential Approach
Specification
Given a list of values, the list is sorted by employing a divide and conquer method that partitions the list into two (roughly) equal sized partitions, followed by recursively sorting each partition and then merging the two resulting sorted partitions into the final sorted list.
Pseudocode
![\displaystyle \textbf{MERGE}(X, Y) \newline \indent L_X \leftarrow \textbf{LENGTH}(X) \newline \indent L_Y \leftarrow \textbf{LENGTH}(Y) \newline \indent L_Z \leftarrow L_X + L_Y \newline \indent Z \leftarrow [L_Z] \newline \indent i, j, k \leftarrow 0, 0, 0 \newline \newline \indent \textbf{while} \quad k < L_Y \newline \indent \indent \textbf{if} \quad i < L_X \land j \ge L_Y \newline \indent \indent \indent \indent Z[k] \leftarrow X[i] \newline \indent \indent \indent \indent i \leftarrow i + 1 \newline \indent \indent \textbf{else-if} \quad i \ge L_X \land j < L_Y \newline \indent \indent \indent \indent Z[k] \leftarrow Y[j] \newline \indent \indent \indent \indent j \leftarrow j + 1 \newline \indent \indent \textbf{else-if} \quad i < L_X \land j < L_Y \newline \indent \indent \indent \textbf{if} \quad X[i] \le Y[j] \newline \indent \indent \indent \indent Z[k] \leftarrow X[i] \newline \indent \indent \indent \indent i \leftarrow i + 1 \newline \indent \indent \indent \textbf{else} \newline \indent \indent \indent \indent Z[k] \leftarrow Y[j] \newline \indent \indent \indent \indent j \leftarrow j + 1 \newline \indent \indent k \leftarrow k + 1 \newline \newline \indent \textbf{return} \quad Z](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Ctextbf%7BMERGE%7D%28X%2C+Y%29++%5Cnewline+%5Cindent+L_X+%5Cleftarrow+%5Ctextbf%7BLENGTH%7D%28X%29++%5Cnewline+%5Cindent+L_Y+%5Cleftarrow+%5Ctextbf%7BLENGTH%7D%28Y%29++%5Cnewline+%5Cindent+L_Z+%5Cleftarrow+L_X+%2B+L_Y++%5Cnewline+%5Cindent+Z+%5Cleftarrow+%5BL_Z%5D++%5Cnewline+%5Cindent+i%2C+j%2C+k+%5Cleftarrow+0%2C+0%2C+0++%5Cnewline++%5Cnewline+%5Cindent+%5Ctextbf%7Bwhile%7D+%5Cquad+k+%3C+L_Y++++%5Cnewline+%5Cindent+%5Cindent+%5Ctextbf%7Bif%7D+%5Cquad+i+%3C+L_X+%5Cland+j+%5Cge+L_Y++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+Z%5Bk%5D+%5Cleftarrow+X%5Bi%5D++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+i+%5Cleftarrow+i+%2B+1++%5Cnewline+%5Cindent+%5Cindent+%5Ctextbf%7Belse-if%7D+%5Cquad+i+%5Cge+L_X+%5Cland+j+%3C+L_Y++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+Z%5Bk%5D+%5Cleftarrow+Y%5Bj%5D++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+j+%5Cleftarrow+j+%2B+1++%5Cnewline+%5Cindent+%5Cindent+%5Ctextbf%7Belse-if%7D+%5Cquad+i+%3C+L_X+%5Cland+j+%3C+L_Y++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Ctextbf%7Bif%7D+%5Cquad+X%5Bi%5D+%5Cle+Y%5Bj%5D++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+Z%5Bk%5D+%5Cleftarrow+X%5Bi%5D++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+i+%5Cleftarrow+i+%2B+1++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Ctextbf%7Belse%7D+++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+Z%5Bk%5D+%5Cleftarrow+Y%5Bj%5D++%5Cnewline+%5Cindent+%5Cindent+%5Cindent+%5Cindent+j+%5Cleftarrow+j+%2B+1++%5Cnewline+%5Cindent+%5Cindent+k+%5Cleftarrow+k+%2B+1++%5Cnewline++%5Cnewline+%5Cindent+%5Ctextbf%7Breturn%7D+%5Cquad+Z++&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
|

|
![\displaystyle \textbf{PARTITION}(X, s, L) \newline \indent Y \leftarrow [L] \newline \indent k \leftarrow 0 \newline \newline \indent \textbf{while} \quad k < L \newline \indent \indent Y[k] \leftarrow X[s + k] \newline \indent \indent k \leftarrow k + 1 \newline \newline \indent \textbf{return} \quad Y](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Ctextbf%7BPARTITION%7D%28X%2C+s%2C+L%29++%5Cnewline+%5Cindent+Y+%5Cleftarrow+%5BL%5D++%5Cnewline+%5Cindent+k+%5Cleftarrow+0++%5Cnewline++%5Cnewline+%5Cindent+%5Ctextbf%7Bwhile%7D+%5Cquad+k+%3C+L++%5Cnewline+%5Cindent+%5Cindent+Y%5Bk%5D+%5Cleftarrow+X%5Bs+%2B+k%5D++%5Cnewline+%5Cindent+%5Cindent+k+%5Cleftarrow+k+%2B+1++%5Cnewline++%5Cnewline+%5Cindent+%5Ctextbf%7Breturn%7D+%5Cquad+Y++&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
Time Complexity
In terms of time complexity, the algorithm is on the order of 
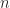
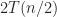
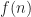


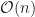
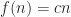
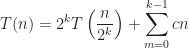
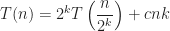
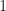





Implementation
In attempting to implement a generic version of merge sort there were a few matters that needed to be addressed. First, the type being sorted required an order relation to be specified so that the merge operation could take place. This is facilitated by restricting the type parameter T to Comparable<T>. Secondly, I had forgotten that you can’t initialize arrays of generics in Java like you can in C# [1]. To workaround this limitation, I settled on specifying the desired operations over implementations of the List<T> interface. Finally, since the List<T> interface makes no guarantees that its implementations provide (near) constant time reading or writing of elements from the list, an additional generic parameter, L, was added so that only those implementations of the List<T> and RandomAccess [2] interfaces could use this implementation of merge sort. The rest of the implementation is a near facsimile of the pseudocode.
package com.wordpress.antimatroid;
import java.util.List;
import java.util.RandomAccess;
public interface IListOperation
<T, L extends List<T> & RandomAccess> {
L execute();
}
package com.wordpress.antimatroid;
import java.util.ArrayList;
import java.util.List;
import java.util.RandomAccess;
public class CopyListOperation
<T, L extends List<T> & RandomAccess>
implements IListOperation<T, L> {
private final L source;
private final int length, initialIndex;
public CopyListOperation(L source, int length, int initialIndex) {
if(source == null)
throw new IllegalArgumentException("source must be non-null.");
if(length < 0)
throw new IllegalArgumentException(String.format(
"length, %d, must be greater than or equal to zero.", length
));
if(initialIndex < 0)
throw new IllegalArgumentException(String.format(
"initialIndex, %d, must be greater than or equal to zero.", initialIndex
));
if(initialIndex + length > source.size())
throw new IllegalArgumentException(String.format(
"initialIndex, %d, + length, %d, must be less than or equal to source.size(), %d.",
initialIndex, length, source.size()
));
this.source = source;
this.length = length;
this.initialIndex = initialIndex;
}
@Override
public L execute() {
L destination = (L) new ArrayList<T>(length);
for(int i = 0; i < length; i++)
destination.add(i, source.get(initialIndex + i));
return destination;
}
}
package com.wordpress.antimatroid;
import java.util.ArrayList;
import java.util.List;
import java.util.RandomAccess;
public class MergeListOperation
<T extends Comparable<T>, L extends List<T> & RandomAccess>
implements IListOperation<T, L> {
private final L a, b;
public MergeListOperation(L a, L b) {
if(a == null)
throw new IllegalArgumentException("a must not be null.");
if(b == null)
throw new IllegalArgumentException("b must not be null.");
this.a = a;
this.b = b;
}
@Override
public L execute() {
int length = a.size() + b.size();
L c = (L) new ArrayList<T>(length);
int i = 0, j = 0;
for(int k = 0; k < length; k++) {
if(i < a.size() && j < b.size()) {
if(a.get(i).compareTo(b.get(j)) <= 0) {
c.add(k, a.get(i++));
} else {
c.add(k, b.get(j++));
}
} else if (i < a.size() && j >= b.size()) {
c.add(k, a.get(i++));
} else if (i >= a.size() && j < b.size()) {
c.add(k, b.get(j++));
} else {
break;
}
}
return c;
}
}
package com.wordpress.antimatroid;
import java.util.List;
import java.util.RandomAccess;
public class MergeSortListOperation <
T extends Comparable<T>,
L extends List<T> & RandomAccess
> implements IListOperation<T, L> {
private final L a;
public MergeSortListOperation(L a) {
if(a == null)
throw new IllegalArgumentException("a must not be null.");
this.a = a;
}
@Override
public L execute() {
if(a.size() <= 1)
return a;
CopyListOperation<T, L> leftPartition
= new CopyListOperation<T, L>(a, (a.size() / 2) + a.size() % 2, 0);
CopyListOperation<T, L> rightPartition
= new CopyListOperation<T, L>(a, (a.size() / 2), (a.size() / 2) + a.size() % 2);
MergeSortListOperation<T, L> leftSort
= new MergeSortListOperation<T, L>(leftPartition.execute());
MergeSortListOperation<T, L> rightSort
= new MergeSortListOperation<T, L>(rightPartition.execute());
MergeListOperation<T, L> merge
= new MergeListOperation<T, L>(leftSort.execute(), rightSort.execute());
return merge.execute();
}
}
Run Time Analysis
Noting that the theoretical time complexity is 



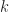
To verify that the implementation follows the theoretical time complexity, increasing values of System.nanoTime() before and after values were used to determine the elapsed time. These values were collected and a total of 50 identical trails were conducted on an Intel Core i7-2630QM CPU @ 2.00 GHz based machine with 6.00 GB RAM.

As presented in the plot, the regressed linear model in logarithmic space yields a satisfactory theoretical curve whose relative error to the empirical curve diminishes to zero as the input size increases.
Parallel Approach
Specification
The parallel implementation operates under the premise that the divide portion of merge sort can be easily parallelized by sorting one partition on the present thread and sorting the other partition on a secondary thread. Once the secondary thread has completed, then the two threads join, and consequently, the two sorted lists are merged. To avoid copious thread creation, whenever the input size is less than a threshold, 
This process can be easily visualized below where each left-hand branch is the originating thread processing the first partition, each right-hand branch is the secondary thread processing the second partition and the junction of those edges represents the consequent merge operation after the secondary thread as joined back in with the originating thread.

Time Complexity
The introduction of parallelism changes the original recurrence relation to the following:

Assuming, 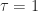

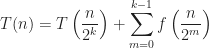
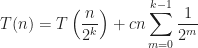
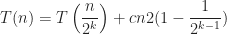


Assuming 


Implementation
In terms of parallelizing the sequential implementation, an addition interface, IThreadedListOperation was added to provide a BeginOperation, EndOperation asynchronous programming model found in the .net world. After looking around the Java world, I didn’t encounter a preferred idiom, so I went with what I knew.
As I mentioned in the sequential approach, the original data structures were going to be arrays which have a guarantee of providing thread safe reads, but not necessarily thread safe writes. To avoid the issue all together, I decided that the IListOperations should always return a new List<T> instance so that only one thread at a time would be reading or manipulating that memory. Since I knew my implementation would not be sharing IListOperations between threads, I decided not to gold plate the implementation with synchronization constructs. If in the future such ability were required, I would go back and modify the code accordingly.
For the parallel implementation I took advantage of the fact that method arguments are evaluated left-to-right [3] to save one some space, but if the specification ever changed, then it would be more appropriate to move the out the leftSort.execute() and rightSort.executeEnd() methods up a line to form a more explicit operation.
package com.wordpress.antimatroid;
import java.util.List;
import java.util.RandomAccess;
abstract public class IThreadedListOperation
<T, L extends List<T> & RandomAccess>
implements Runnable, IListOperation<T, L> {
private Thread thread;
public void executeBegin() {
if(thread != null)
throw new IllegalStateException();
thread = new Thread(this);
thread.start();
}
public L executeEnd() {
if(thread == null)
throw new IllegalStateException();
try {
thread.join();
} catch (InterruptedException e) {
}
return getResult();
}
public L execute() {
if(thread != null)
throw new IllegalStateException();
run();
return getResult();
}
abstract protected L getResult();
}
package com.wordpress.antimatroid;
import java.util.List;
import java.util.RandomAccess;
public class MergeSortThreadedListOperation
<T extends Comparable<T>, L extends List<T> & RandomAccess>
extends IThreadedListOperation<T, L> {
private final L a;
private L b;
private final int threshold;
public MergeSortThreadedListOperation(L a) {
this(a, 1024);
}
public MergeSortThreadedListOperation(L a, int threshold) {
if(a == null)
throw new IllegalArgumentException("a must be non-null.");
if(threshold <= 0)
throw new IllegalArgumentException("threshold must be greater than zero.");
this.a = a;
this.threshold = threshold;
}
@Override
public void run() {
if(a.size() <= 1) {
b = a;
return;
}
if(a.size() <= threshold) {
MergeSortListOperation<T, L> mergeSort = new MergeSortListOperation<T, L>(a);
b = mergeSort.execute();
return;
}
CopyListOperation<T, L> leftPartition
= new CopyListOperation<T, L>(a, (a.size() / 2) + a.size() % 2, 0);
MergeSortThreadedListOperation<T, L> leftSort
= new MergeSortThreadedListOperation<T, L>(leftPartition.execute());
CopyListOperation<T, L> rightPartition
= new CopyListOperation<T, L>(a, (a.size() / 2), (a.size() / 2) + a.size() % 2);
MergeSortThreadedListOperation<T, L> rightSort
= new MergeSortThreadedListOperation<T, L>(rightPartition.execute());
rightSort.executeBegin();
MergeListOperation<T, L> merge
= new MergeListOperation<T, L>(leftSort.execute(), rightSort.executeEnd());
b = merge.execute();
}
@Override
protected L getResult() {
return b;
}
}
Run Time Analysis
Noting that the time complexity for the parallel approach is
The trial methodology used in the sequential run time analysis is used once again to produce the following plot. Note that it begins at 2048 instead of 1. This was done so that only the parallel implementation was considered and not the sequential implementation when the input size is 

As presented in the plot, the regressed linear model in logarithmic space yields a satisfactory theoretical curve whose relative error to the empirical curve diminishes to zero as the input size increases.
Threshold Selection
As a thought experiment, it makes sense that as the threshold approaches infinity, that there is no difference between the sequential implementation and parallel one. Likewise, as the threshold approaches one, then the number of threads being created becomes exceedingly large and as a result, places a higher cost on parallelizing the operation. Someplace in the middle ought to be an optimal threshold that yields better run time performance compared to the sequential implementation and a pure parallel implementation. So a fixed input size should produce a convex curve as a function of the threshold and hence have a global minimum.

Conducting a similar set of trials as the ones conducted under the analysis of the sequential run time give a fully parallel and sequential curve which to evaluate where the optimal threshold resides. As the plot depicts, as the threshold approaches one, there is an increase in the processing taking the form of a convex curve. As the threshold exceeds the input size, then the sequential approach dominates. By conducting a Paired T-Test against the means of the two curves at each input size, 1024 was determined to be the optimal threshold based on the hardware used to conduct the trials. As the input size grows, it is evident that for thresholds less than 1024, the sequential approach requires less time and afterwards, the parallel approach is favorable.
Conclusion
In comparing the sequential and parallel implementations it was observed that the specified parallel implementation produced as much as a 2.65 factor improvement over the specified sequential implementation for megabyte sized lists.

Larger sized lists exhibited a declining improvement factor. It is presumed that as the input size grows that the amount of memory being created is causing excessive paging and as a result increasing the total run time and consequently reducing the improvement factor. To get around this limitation, the algorithm would need to utilize an in-place approach and appropriate synchronization constructs put into place to guarantee thread safety.
From a theoretical point of view, the improvement factor is the ratio of the run time of the sequential implementation to the parallel implementation. Using the time complexities presented, 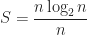
Footnotes
[1] This design decision is discussed in §4.7 of the Java Language Specification (3rd Edition) on reifiable types.
[2] The only two java.util classes providing this guarantee are ArrayList and Vector. Both of which implement the interface RandomAccess which is intended indicate that the class provides the (near) constant reading and writing of elements.
[3] The left-to-right order of operations is specified by §15.7.4 of the Java Language Specification (3rd Edition). Also worth noting the specification recommends against the practice of relying on this convention however in §15.7:
… It is recommended that code not rely crucially on this specification. Code is usually clearer when each expression contains at most one side effect, as its outermost operation, and when code does not depend on exactly which exception arises as a consequence of the left-to-right evaluation of expressions.

How to exactly run the code above? i got the code into classes but how to implement and pass the parameters into a main class?
red
2014-06-12 at 11:41 am