Posts Tagged ‘Image Processing’
Category Recognition of Golden and Silver Age Comic Book Covers
Introduction
Motivation
For a while now, I’ve been wanting to work on a computer vision project and decided for my next research focused project that I would learn some image processing and machine learning algorithms in order to build a system that would classify the visual contents of images, a category recognizer. Over the course of the summer I researched several techniques and built the system I had envisioned. The end result is by no means state of the art, but satisfactory for four months of on-and-off development and research. The following post includes my notes on the techniques and algorithms that were used in the project followed by a summary of the system and its performance against a comic book data set that was produced during development.
Subject Matter
The original subject matter of this project were paintings from the 1890s done in the Cloisonnism art style. Artists of the style are exemplified by Emile Bernard, Paul Gaugin and Paul Serusier. The style is characterized by large regions of flat colors outlined by dark lines; characteristics that would be easy to work with using established image processing techniques. During development, it became evident that no one approach would work well with these images. As an alternative, I decided to work with Golden and Silver Age comic book covers from the 1940s to 1960s which also typified this art style. Many of the comic books were drawn by the same individuals such as Jack Kirby, Joe Shuster and Bob Kane. As an added benefit, there are thousands of comic book covers available online compared to the dozens of Cloisonnism paintings.
Image Processing
Representation
An image is a function, 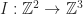
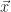
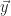

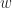
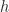

|
Like any other vector field, transformations can be applied to the image to yield a new image, 
There are many different instances of these types of filters, but only those used in this project are discussed below. Computational complexity and efficient algorithms for each type of filter are also discussed where appropriate.
Point-based Filters
Point-based filters, 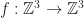
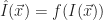

Grayscale Projection
It is helpful to collapse the RGB channels of an image down to a single channel for the purpose of simplifying filter results. This can be done by using a filter of the form 
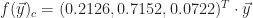
Thresholding
A threshold filter serves as a way to accentuate all values in the image greater than or equal to a threshold, 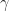
The first variety is the step threshold filter, 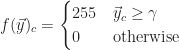
The second variety is a logistic threshold filter, 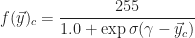
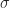

|
 ), logistic threshold filter (
), logistic threshold filter (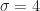 ), and logistic threshold filter (
), and logistic threshold filter (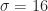 ).
). Neighbor-based Filters
All neighbor-based filters take the output vectors neighboring an input vector to calculate a new output vector value. How the neighboring output vectors should be aggregated together is given by a kernel image, 
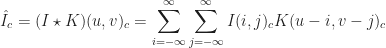
Neighbor-based filters can be applied naïvely in quartic time as a function of the image and kernel dimensions, 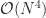
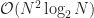
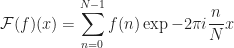
The Discrete Fourier Transform is a way of converting a signal residing in the spatial domain into a signal in the frequency domain by aggregating waveforms of varying frequencies where each waveform is amplified by its corresponding value in the input signal. The Inverse Discrete Fourier Transform maps a frequency domain signal back to the spatial domain.

Applying the Discrete Fourier Transform to a convolution, 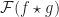
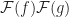
The improved time complexity is achieved by using a divide a conquer algorithm known as the Fast Fourier Transform which takes advantage of the Danielson-Lanczos Lemma which states that the Discrete Fourier Transform of a signal can be calculated by splitting the signal into two equal sized signals and computing their Discrete Fourier Transform.
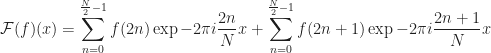

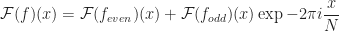
For the purposes of image processing, we use the two-dimensional Discrete and Inverse Discrete Fourier Transform.
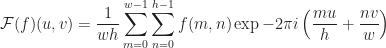
The expression can be rearranged to be the Discrete Fourier Transform of each column in the image and then computing the resulting Discrete Fourier Transform of those results to obtain the full two-dimensional Discrete Fourier Transform.
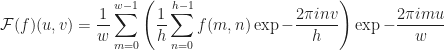
As a result, we can extend the Fast Fourier Transform in one dimension easily into two dimensions producing a much more efficient time complexity.
Weighted Means: Gaussian and Inverse Distance
Weighted mean filters are used to modify the morphology of an image by averaging neighboring output vectors together according to some scheme.
A Gaussian filter is used to blur an image by using the Gaussian distribution with standard deviation,
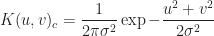
The inverse distance filter calculates how far the neighboring output vectors are with respect to the new output vector being calculated. Each result is also scaled by the parameter,

Laplacian
A Laplacian filter detects changes in an image and can be used for sharpening and edge detection. Much like in calculus of a single variable, the slope of a surface can be calculated by the Gradient operator, 

Since an image is a discrete function, the Laplacian operator needs to be approximated numerically using a central difference. 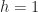



|
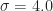 ), inverse distance filter (
), inverse distance filter ( ) and Laplacian filter.
) and Laplacian filter. Image-based Filters
Image-based filters calculate some information about the contents of the image and then use that information to generate the appropriate point-based and neighbor based filters.
Normalization
The normalization process computes the minimum, 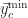

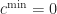
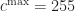
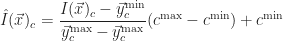
This particular image-based filter can be applied in quadratic time,

|
Edge Detection
Edge detection is the process of identifying changes (e.g., texture, color, luminance and so on) in an image. As alluded to in the image processing section, the Laplacian filter is central to detecting edges within an image. As a result A sequence of filters is used before and after a Laplacian filter to produce a detector that consistently segments comic book covers. The following sequence of filters was used.
- Grayscale Projection – Since all logical components of a comic book cover are separated by inked lines, it is permissible to ignore the full set of RGB channel information and collapse the image down to a grayscale image.
- Normalization – It is conceivable that the input image has poor contrast and brightness. To ensure that the full range of luminescence values are presented, the image is normalized.
- Gaussian (
) – An image may have some degree of noise superimposed on the image. To reduce the noise, the image is blurred using a Gaussian filter with a standard deviation of
. This is enough to smooth out the image without distorting finer image detail.
- Laplacian – Once the image has been prepared, its edges are calculated using the Laplacian filter.
- Normalization – Most of the changes in the image may be subtle and need to make sure that all edge information is accentuated as much as possible by applying a normalization filter.
- Step Threshold (
) – Since a partial edge isn’t particularly useful information, any edge RGB value less than
is attenuated to zero and all other values accentuated to
- Inverse Distance (
) – It is possible that during the threshold process that discontinuities were introduced into some of the edges. To mitigate this impact, an inverse distance filter is used to inflate existing edges and intensify the result with a gain of
 |
The complete edge detection process takes computational complexity of
Segmentation
With the edge image it is possible to segment the image into its visual components. This is achieved by doing a flood fill on the image and using the edge image as the boundaries for the fill. Once the fill runs out of points to flood, the segment is complete and the next remaining point in the image is considered. To reduce the number of minuscule segments, only those segments representing 

|
Machine Learning
Classifiers
The task of classification is to identify decision boundaries separating all of the classification within the data set. Such data sets can be linearly or non-linearly separable and as a result, classifiers were developed to solve the linear case and then adapted to deal with the more complicated non-linear case. While there are a number of classifiers, only the K-Nearest Neighbor and Support Vector Machine classifiers were researched and implemented in this project.
K-Nearest Neighbor
The K-Nearest Neighbor classifier is an online classifier which operates under the assumption that a yet to be classified vector is most likely to be the same classification as those 

Distance can be measured in a variety of ways for arbitrary vectors, 

The Manhattan distance, 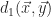


Two factors affect the efficacy of the algorithm. The first is the dimension of the data, 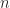

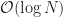

|
Support Vector Machine
Formulation
The Support Vector Machine classifier is an offline linear, binary classifier which operates under the assumption that a training set, 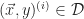
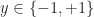
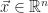

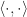
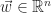
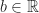
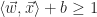

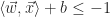


|
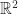 .
.
The hyperplane is padded by two hyperplanes separated by an equal distance to the nearest training examples of each classification. The span between the supporting hyper planes is the margin. The goal then is to pick a hyperplane which provides the largest margin between the two separable classifications. The margin between the supporting hyperplanes is given by 
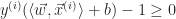
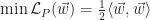

To find the optimal parameters, it is easier to translate the problem into a dual form by applying the technique of Lagrange Multipliers. The technique takes an objective function, 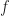



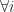
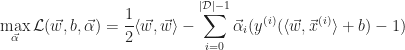
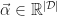

The next step is to differentiate the objective function with respect to the parameters to determine the optimal solution. Since the function is concave, the results will yield the desired maximum constraints.
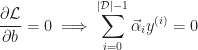
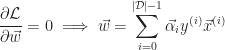
As a result the dual problem can be written as the following:
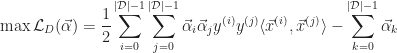
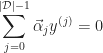
Handling of non-linearly separable data
In the event that the data is not linearly separable, then an additional parameter, 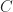

Non-linear classification
By way of Mercer’s Theorem, the linear Support Vector Machine can be modified to allow for non-linear classification through the introduction of symmetric, positive semidefinite kernel functions, 

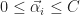
And the decision hyperplane function then becomes:
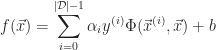
The following are some typical kernels:
- Linear –
- Polynomial –
- Radial basis function –
- Sigmoid –


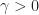
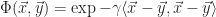
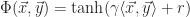
From a practical point of view, only the linear and radial basis function kernels from this list should be considered since the polynomial kernel has too many parameters to optimize and the sigmoid kernel does not satisfy the positive semidefinite kernel matrix requirement of Mercer’s Theorem.
Algorithmic details
The Support Vector Machine classifier can be implemented using a quadratic programming solver or by incremental descent algorithms. Both methods work, but are difficult to implement and expensive to procure. An alternative is the Sequential Minimal Optimization algorithm developed by John Platt at Microsoft Research. The algorithm works by analytically solving the dual problem for the case of two training examples then iterating over all of the lagrange multipliers verifying that the constraints are satisfied. For those that are not, the algorithm computes new lagrange multiplier values. The full details of the algorithm can be found in Platt’s paper.
The time complexity of the algorithm is quadratic with respect to the number of training samples and support vectors
The time complexity of evaluating the decision function is linear with respect to the number of support vectors 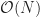
Multiclass Classification
The classification methods presented in the previous section are utilized as binary classifiers. These classifiers can be used to classify multiple classifications by employing a one-vs-all or all-vs-all approach. In the former a single classification is separated from the remaining classifications to produce
In the latter, a single classification is compared individually to each other classification resulting in 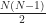
Both methods have their place. The benefit of a one-vs-all approach is that there are fewer classifiers to maintain. However, training a single classifier on a complete data set is time consuming and can give deceptive performance measures. All-vs-all does result in more classifiers, but it also provides for faster training which can be easily parallelized on a single machine and distributed to machines on a network.
Classifier Evaluation
Individual classifiers are evaluated by training the classifier against a data set and then determining how many correct and incorrect classifications were produced. This evaluation produces a confusion matrix.
| Predicted Classification | ||||
|---|---|---|---|---|
| Positive | Negatives | Total | ||
| Actual Classification | Positive | (TP) True Positive | (FN) False Negative | (AP) Actual Positives |
| Negatives | (FP) False Positive | (TN) True Negative | (AN) Actual Negatives | |
| Total | (PP) Predicted Positives | (PN) Predicted Negatives | (N) Examples | |
The confusion matrix is used to calculate a number of values which are used to evaluate the performance of the classifier. The first of which is the accuracy and error of the classifier. Accuracy measures the number of instances where the actual and predicted classifications matched up and the error for when they do not.
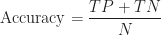

Since we should expect to get different results each time we evaluate a classifier, the values that we obtain above are sample estimates of the true values that are expected. Given enough trails and measurements, it is possible to determine empirically what the true values actually are. However, this is time consuming and it is instead easier to use confidence intervals to determine what interval of values a measurement is mostly likely to fall into.
Training and Testing
Each of the classifiers presented have some number of parameters that must be determined. The parameters can be selected by having some prior knowledge or by exploring the parameter space and determining which parameters yield optimal performance. This is done by performing a simple grid search over the parameter space and evaluating and attempting to minimize the error.
K-folds cross-validation is used at each grid location to produce a reliable measure of the error. The idea is that a data set is split into 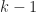
System
Implementation
The system was implemented in C# 4.0 on top of the Microsoft .NET Framework. The user interface was written by hand using the WinForms library. No other third-party libraries or frameworks were used. When possible, all algorithms were parallelized to take advantage of multi-core capabilities to improve processing times.
Summary
The system consists of two modes of operation: training and production. In training, a human classifier labels image segments with an appropriate classification. New image segments are then taken into consideration during the training of machine learning algorithms. Those algorithms producing the lowest error for a given classification are then used in production mode. During production, a user submits an image and each image segment is then evaluated against the available classifiers. Those image segments are then presented to the user with the most likely classification. These two modes along with their workflows and components are illustrated in the following diagram.

|
Training Mode
Data Set Construction
The user interface of the system allows users to add an image segment to a local data set of images. Once added, the image is then processed to yield image segments. The user can then label an image segment by editing the segment and moving on to the next image segment. This allows for easy and efficient human classification of data. If the user does not wish to keep the image, he or she may remove the image from the data set as well.

|
Data Set Cleaning
During the construction phase, errors may be introduced into the data set typically in the case of typos or forgetting which segment was currently being edited. The data set is cleaned by listing out all available classifications and presenting the user with all available segments associated with that classification. The user can then review the image segment as it was identified in the source image. If the user does not wish to keep the classification, he or she may remove the image from the data set as well.

|
Data Set Statistics
The data set consists of 496 comic book covers pulled from the Cover Browser database of comic book covers. The first 62 consecutive published comic book covers where used from Action Comics, Amazing Spider-man, Batman, Captain America, Daredevil, Detective Comics, Superman, and Wonder Woman and then processed by the image processing subsystem yielding 24,369 image segments. 11,463 of these segments represented classifiable segments which were then labeled by hand over the course of two weeks; the remaining segments were then discarded.

|
In total, there were 239 classifications identified in the data set among 18 categories. Text, clothing, geography, and transportation categories accounting for 90% of the data set. Since the majority of classification were incidental, only those classifications having 50 or more image segments were considered by the application leaving a total of 38 classifications.
Classifier Evaluation
For the 38 classifications meeting the minimum criteria for classification, the K-Nearest Neighbor approach worked well in distinguishing between text classifications from other classifications and between intra-text classifications for both all-vs-all and one-vs-all schemes.

|

|
| All-vs-All K-Nearest Neighbor Performance. | One-vs-All K-Nearest Neighbor Performance. |
The Support Vector Machine approach presented unremarkable results for both all-vs-all and one-vs-all methods. In the former, only a few pairings resulted in acceptable error rates whereas the later presented only a couple acceptable error rates.

|

|
| All-vs-All Support Vector Machine Performance. | One-vs-All Support Vector Machine Performance. |
For both classification methods presented, the all-vs-all method yielded superior results to the one-vs-all method. In comparing the two classifier methods, the K-Nearest Neighbor seems to have done better than the Support Vector Machine approach, contrary to what was expected from literature. Both classifier methods are used in production mode.
Production Mode
Production mode allows the end user to add an image to the data set and then review the most likely classifications produced by evaluating each image segment against the available set of classifiers. The end user is then expected to review each segment and accept or reject the suggested classification. Aside from this additional functionality, production mode is nearly identical in functionality to training mode.

|
Conclusions
The time spent on this project was well spent. I met the objectives that I laid out at the beginning of the project and now have a better understanding of the image processing algorithms and machine learning concepts from a theoretical and practical point of view.
Future Work
Segmentation
One issue with the existing implementation is that it over segments the image. Ideally, fewer segments would be produced that are more closely aligned with their conceptual classification. There are a number of popular alternatives to the approach taken, such as level set methods, which should be further investigated.
Classification
The approach taken to map scaled versions of the image segments to a 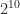
System User Interface
While it was disappointing to have spent so much time building a data set only to have to limit what was considered, it assisted me in building a user interface that had to be easy and fast to use. The application can certainly be developed further and adapted to allow for other data sets to be constructed, image segmentation methods to be added and additional classifications to be evaluated.
System Scalability
The system is limited now to a single machine, but to grow and handle more classifications, it would need to be modified to run on multiple machines, have a web-based user interface developed and a capable database to handle the massive amounts of data that would be required to support a data set on the scale of the complete Cover Browser’s or similar sites’ databases (e.g., 450,000 comic book covers scaled linearly would require 546 GiB of storage.) Not to mention data center considerations for overall system availability and scalability.
References
Aly, Mohamed. Survey on Multiclass Classification Methods. [pdf] Rep. Oct. 2011. Caltech. 24 Aug. 2012.
Asmar, Nakhle H. Partial Differential Equations: With Fourier Series and Boundary Value Problems. 2nd ed. Upper Saddle River, NJ: Pearson Prentice Hall, 2004. Print.
Bousquet, Olivier, Stephane Boucheron, and Gabor Lugosi. “Introduction to Statistical Learning Theory.” [pdf] Advanced Lectures on Machine Learning 2003,Advanced Lectures on Machine Learning: ML Summer Schools 2003, Canberra, Australia, February 2-14, 2003, Tübingen, Germany, August 4-16, 2003 (2004): 169-207. 7 July 2012.
Boyd, Stephen, and Lieven Vandenberghe. Convex Optimization [pdf]. N.p.: Cambridge UP, 2004. Web. 28 June 2012.
Burden, Richard L., and J. Douglas. Faires. Numerical Analysis. 8th ed. Belmont, CA: Thomson Brooks/Cole, 2005. Print.
Caruana, Rich, Nikos Karampatziakis, and Ainur Yessenalina. “An Empirical Evaluation of Supervised Learning in High Dimensions.” [pdf] ICML ’08 Proceedings of the 25th international conference on Machine learning (2008): 96-103. 2 May 2008. 6 June 2012.
Fukunaga, Keinosuke, and Patrenahalli M. Narendra. “A Branch and Bound Algorithm for Computing k-Nearest Neighbors.” [pdf] IEEE Transactions on Computers (1975): 750-53. 9 Jan. 2004. 27 Aug. 2012.
Gerlach, U. H. Linear Mathematics in Infinite Dimensions: Signals, Boundary Value Problems and Special Functions. Beta ed. 09 Dec. 2010. Web. 29 June 2012.
Glynn, Earl F. “Fourier Analysis and Image Processing.” [pdf] Lecture. Bioinformatics Weekly Seminar. 14 Feb. 2007. Web. 29 May 2012.
Gunn, Steve R. “Support Vector Machines for Classification and Regression” [pdf]. Working paper. 10 May 1998. University of Southampton. 6 June 2012.
Hlavac, Vaclav. “Fourier Transform, in 1D and in 2D.” [pdf] Lecture. Czech Technical University in Prague, 6 Mar. 2012. Web. 30 May 2012.
Hsu, Chih-Wei, Chih-Chung Chang, and Chih-Jen Lin. A Practical Guide to Support Vector Classification. [pdf] Tech. 18 May 2010. National Taiwan University. 6 June 2012.
Kibriya, Ashraf M. and Eibe Frank. “An empirical comparison of exact nearest neighbour algorithms.” [pdf] Proc 11th European Conference on Principles and Practice of Knowledge Discovery in Databases. (2007): 140-51. 27 Aug. 2012.
Marshall, A. D. “Vision Systems.” Vision Systems. Web. 29 May 2012.
Panigraphy, Rina. Nearest Neighbor Search using Kd-trees. [pdf] Tech. 4 Dec. 2006. Stanford University. 27 Aug. 2012.
Pantic, Maja. “Lecture 11-12: Evaluating Hypotheses.” [pdf] Imperial College London. 27 Aug. 2012.
Platt, John C. “Fast Training of Support Vector Machines Using Sequential Minimal Optimization.” [pdf] Advances in Kernel Methods – Support Vector Learning (1999): 185-208. Microsoft Research. Web. 29 June 2012.
Sonka, Milan, Vaclav Hlavac, and Roger Boyle. Image Processing, Analysis, and Machine Vision. 2nd ed. CL-Engineering, 1998. 21 Aug. 2000. Web. 29 May 2012.
Szeliski, Richard. Computer vision: Algorithms and applications. London: Springer, 2011. Print.
Tam, Pang-Ning, Michael Steinbach, and Vipin Kumar. “Classification: Basic Concepts, Decision Trees, and Model Evaluation.” [pdf] Introduction to Data Mining. Addison-Wesley, 2005. 145-205. 24 Aug. 2012.
Vajda, Steven. Mathematical programming. Mineola, NY: Dover Publications, 2009. Print.
Welling, Max. “Support Vector Machines“. [pdf] 27 Jan. 2005. University of Toronto. 28 June 2012
Weston, Jason. “Support Vector Machine (and Statistical Learning Theory) Tutorial.” [pdf] Columbia University, New York City. 7 Nov. 2007. 28 June 2012.
Zhang, Hui, Jason E. Fritts, and Sally A. Goldman. “Image Segmentation Evaluation: A Survey of Unsupervised Methods.” [pdf] Computer Vision and Image Understanding 110 (2008): 260-80. 24 Aug. 2012.
Copyright
Images in this post are used under §107(2) Limitations on exclusive rights: Fair use of Chapter 1: Subject Matter and Scope of Copyright of the of the Copyright Act of 1976 of Title 17 of the United States Code.
